Loading and Preparing Data¶
This section shows how to load microdata into sdcApp and prepare the data for the SDC process.
The first step in the SDC process is loading the dataset into sdcApp. sdcApp supports most common statistical data formats, such as R, STATA, SPSS, SAS and csv files. First-time users may also load one of the two practice datasets, which are included in sdcApp, to explore sdcApp and methods. Most examples in this guide are illustrated by using the practice dataset testdata and can be reproduced by using this dataset.
After loading the data, the user needs to prepare the data for the SDC process. Most preparation steps can be carried out in sdcApp, although users may find it more convenient to perform some of these actions in another statistical software before loading the data in sdcApp.
Loading data¶
Practice datasets¶
sdcApp includes two practice datasets: testdata and testdata2. The dataset testdata is used to illustrate methods and examples in this guide. In order to replicate these examples, the user needs to load this dataset. In order to load the testdata dataset, navigate to the Microdata tab and select Testdata/Internal data in the left sidebar. Select the dataset from the dropdown menu and click the button Load data. This is illustrated in Fig. 16.
Note
Any other datasets loaded in the current R session are also shown in the dropdown list with available datasets and can be loaded.
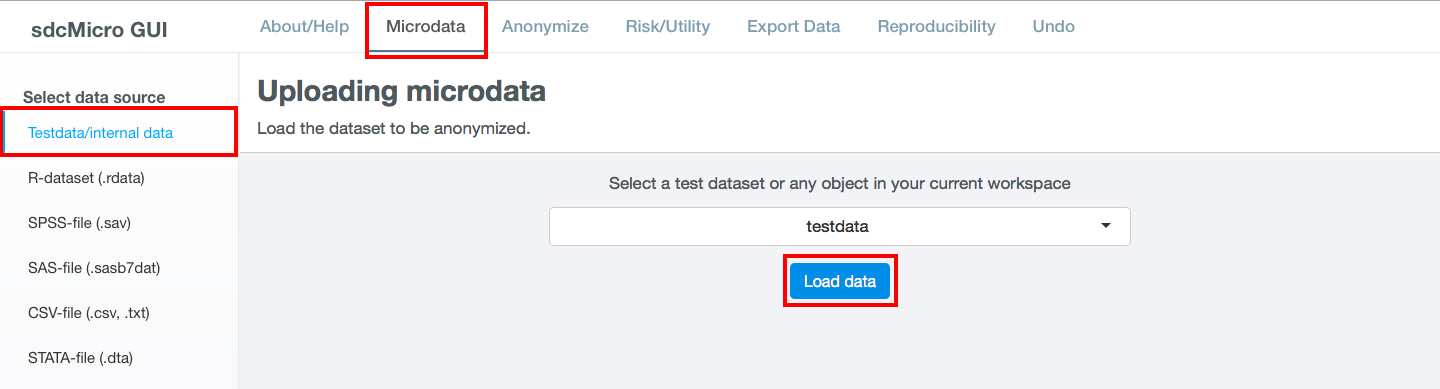
Fig. 16 Load testdata on Microdata tab
After loading the dataset, the data is displayed in the Microdata tab. The Microdata tab changes and the functionality for loading microdata is replaced by functionality for exploring and preparing the dataset (cf. Fig. 17). The left sidebar shows different options to explore and prepare the data for the anonymization process, as discussed in the next sections.
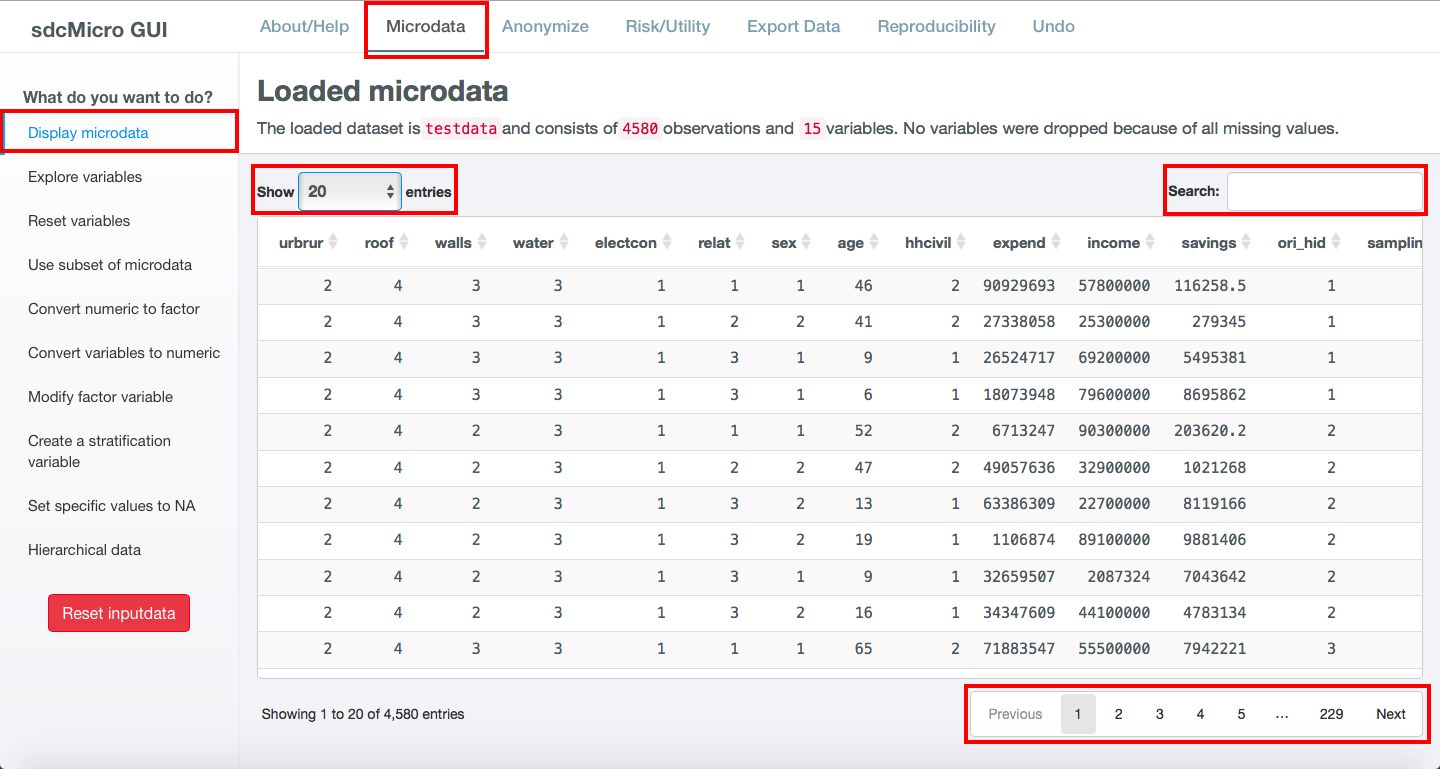
Fig. 17 Loaded testdata dataset on Microdata tab
After loading the testdata dataset, the loaded
dataset is displayed (cf. Fig. 17). By default the first 20 records are displayed.
With the dropdown menu in the topleft corner it is possible to display 20, 50, 100 or all
records per page. It is not recommended to select All in case of larger datasets as
sdcApp will run very slowly. In the right-bottom corner of the screen it is possible to navigate to different pages,
either by clicking Next or by clicking on a page number. The table
with the data is both horizontally and vertically scrollable with the scrollbars on the
right side and bottom of the table. To sort the data by a variable, click on the symbol
with two arrows ( or
or  ) next to the variable name in the header of the table.
The data is searchable by using the search bar on the right top of the table. Only records
with matches are displayed. The search is performed simultaneously on all variables.
) next to the variable name in the header of the table.
The data is searchable by using the search bar on the right top of the table. Only records
with matches are displayed. The search is performed simultaneously on all variables.
Your microdata¶
Besides the native R format, sdcApp supports datasets in several other common data formats (cf. Table 1). If the microdata is not in one of these data formats, another software can be used to convert the data, such as Stat/Transfer. Also some statistical software allow to export data in another data format.
| Software | File extension |
|---|---|
| R/RStudio | .rdata |
| SPSS | .sav |
| SAS | .sas7bdat |
| STATA | .dta |
| csv | .csv, .txt |
In order to load a dataset, select the corresponding data format from the left sidebar of the Microdata tab. For all formats the user can set two options (cf. Fig. 18):
- Convert string variables (character vectors) to factor variables?
- If
TRUE(default), variables of type string are automatically converted to categorical variables (type factor in R). Categorical variables need to be of type factor in sdcApp. Remove any textual string variables, such as ‘Specify other:’ variables before loading the data. These variables are oftentimes not suitable for release and require long computation times to be transformed to factor. IfFALSE, string variables are read as vectors of type character.
- Drop variables with only missing values (NA)?
- If
TRUE(default), variables that contain only missing values (NAin R) are removed upon loading the data. This does not cause any loss of information, as these variables do not contain information. However, variables with only missing values can cause issues in sdcApp. IfFALSE, no variables are deleted.
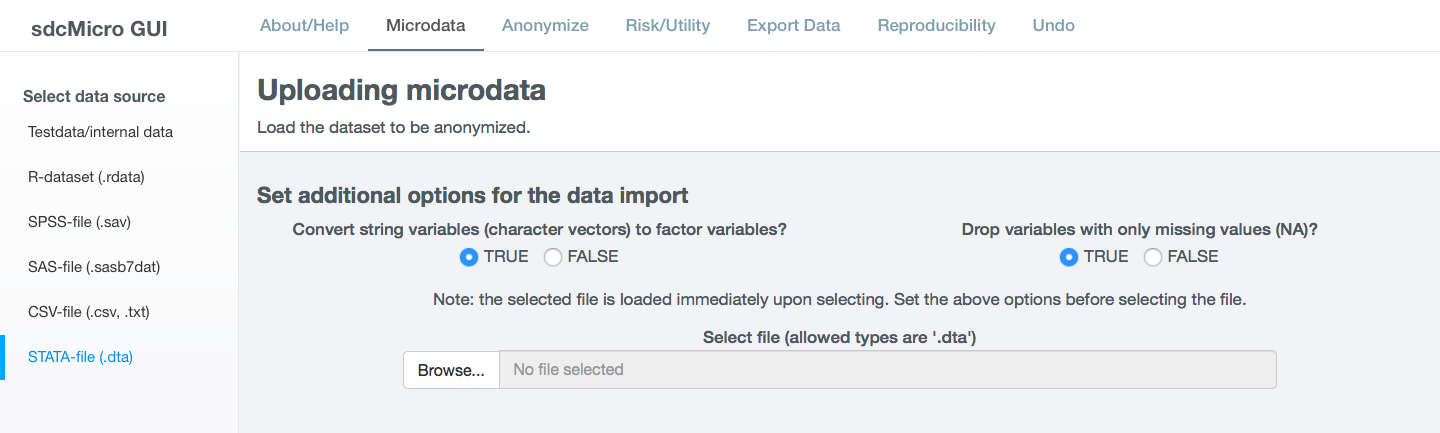
Fig. 18 Load data on Microdata tab - example STATA dataset
If the selected data format is a csv file, two additional options need to be specified:
- Does the first row contain the variable names?
- If
TRUE, the values in the first row are used as variable names. IfFALSE, the variables names are set to V1, V2, V3, … in the order of appearance in the dataset.
- Field separator
- The field separator in the csv file needs to be specified. Options are comma (,), semicolon (;) and tab.
After setting the options for the data upload, click on the button Browse to access the file system in your computer and select the microdata file. The file is uploaded immediately after selection. After loading the file, which may
Note
Set the additional options before selecting the datafile from your file system. Upon selection after clicking Browse, the file is immediately loaded and settings can no longer be changed. If the file was accidentally loaded before setting all parameters, the file needs to be reloaded after first restting the microdata by clicking Reset microdata in the left sidebar.
Note
The default maximum file size in sdcApp is 50 MB. In order to upload larger files,
the maximum file size in MB needs to be specified upon launching sdcApp. This can
be achieved by specifying the argument maxRequestSize:
1 2 | # Launch sdcApp with increased max. file size (200MB) sdcApp(maxRequestSize = 200) |
After loading, the dataset is displayed. By default the first 20 records are displayed. With the dropdown menu in the topleft corner it is possible to display 20, 50, 100 or all records per page. It is not recommended to select all in case of larger datasets sdcApp will run very slow. In the right bottom it is possible to navigate to different pages, either by clicking Next or by clicking on a page number. The table with the data is both horizontally and vertically scrollable with the scrollbars on the right side and bottom of the table. To sort the data by a variable, click on the symbol with two arrows next to the variable name in the header of the table.
After loading the dataset, the data is shown in the Microdata tab. The Microdata tab changes and the functionality for loading microdata is replaced with functionality to explore and prepare the dataset (cf. Fig. 19). The left sidebar shows different options to explore and prepare the data for the anonymization process, as discussed in the next sections.
Inspect and explore data¶
After loading the dataset into sdcApp, the data is shown on the Microdata tab. At the top of the data viewer, the file name, the number of observations and variables is shown as well as the number of variables that were deleted as a result all missing values (cf. Fig. 19).
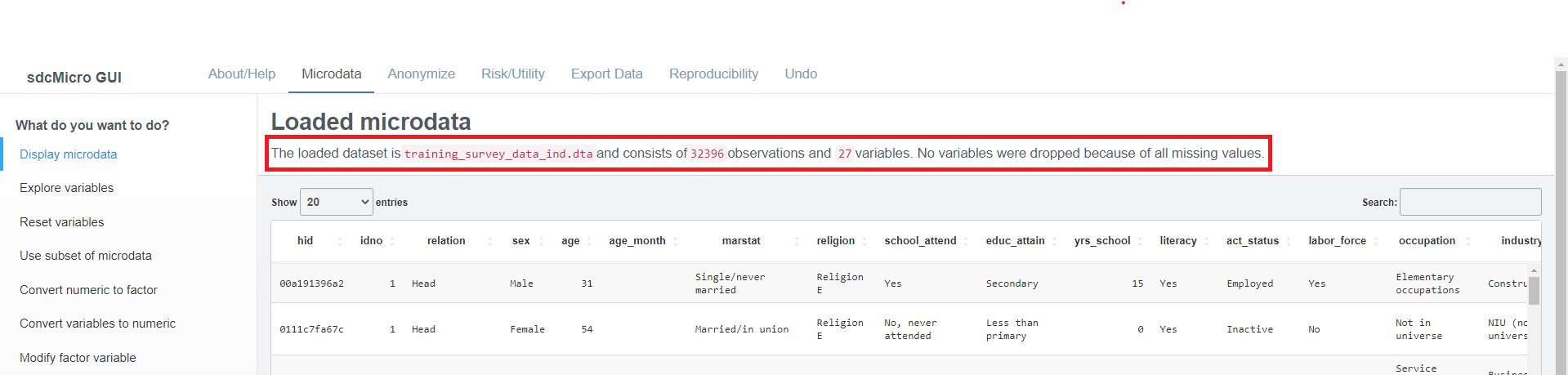
Fig. 19 The file name, number of observations and variables shown after loading a dataset.
Note
If the option Drop variables with only missing values (NA)? is set to TRUE, the number of variables shown may be lower than the number of variables in the loaded dataset.
It is important to check whether the data was imported completely and correctly by browsing the dataset in sdcApp. If, for example, records are missing or labels are corrupted, these issues need to be fixed outside of sdcApp and the data need to be reimported.
By clicking Explore variables in the left sidebar, univariate and bivariate summary statistics appropriate for the variable type can displayed. If one variable is selected, univariate summary statistics are shown.
Note
The choice of summary statistics is based on the variable type specified in R (shown in brackets after the variable name, e.g., urbrur (integer)). Therefore, the representation may not be correct, if the variable type does not correspond with the variable content. By converting the variable (see Convert variable type), the correct summary statistics will be displayed.
Preparing data¶
Most datasets need to be prepared before the start of the anonymization process. Examples of data preparation steps are adding labels, correcting errors, removing variables that are not suitable for release, converting the variable type, creating stratification variables and subsetting in case of hierarchical data. It is recommended to carry out the data preparation in a statistical software of choice, before loading the data in sdcApp.
After loading the data in sdcApp, still some steps may need to be carried, which are specific to the needs of the sdcApp. These steps are discussed in the following subsections.
Convert variable type¶
R uses different variable types. Common variables types are character (string variables), factor (categorical variables), integer and numeric. In order to carry out the SDC process in sdcApp, categorical varables need to be of type factor or integer. Numerical variables need to be of type numeric or integer. This is epecially important if variables are selected as key variables (see Section Variable selection).
Most of the time variables have the correct type after loading in sdcApp. However, in some instances, the variable type needs to be changed after loading the data. For example, a categorical variable without variable labels may be read in as numeric variables or a numeric variable that has a one or more values with a label (e.g. missing value code or not applicable code) may be stored as factor variable. In some cases, this can be solved by changing the labels in the original data and reload the data. However, this may not always be desirable, for instance, in the example of one vlue in a numeric variable that is labelled. In these cases, the variable type must be changed in sdcApp. sdcApp allows to convert numeric variable to factor variables (for categorical variables) and character and factor variables to numeric.
Convert variables to factor
Convert variables to numeric
Note
Case of variable age - typically numeric, but want to use as categorcial key var -> need to
Set specific values to NA¶
Missing values play an important role in anonymization of microdata. In particular when
measuring disclosure risk of categorical key variables (see `Risk`__). sdcApp only considers
the R missing value NA as missing. Therefore, it is important to recode other missing values,
such as 9, 99, 998 or 999, “Missing”, “Not applicable” after loading the
data to the R missing value NA, if appropriate. Many standard missing value codes
in the data, such as . in STATA are automatically converted to NA upon loading
the data into sdcApp.
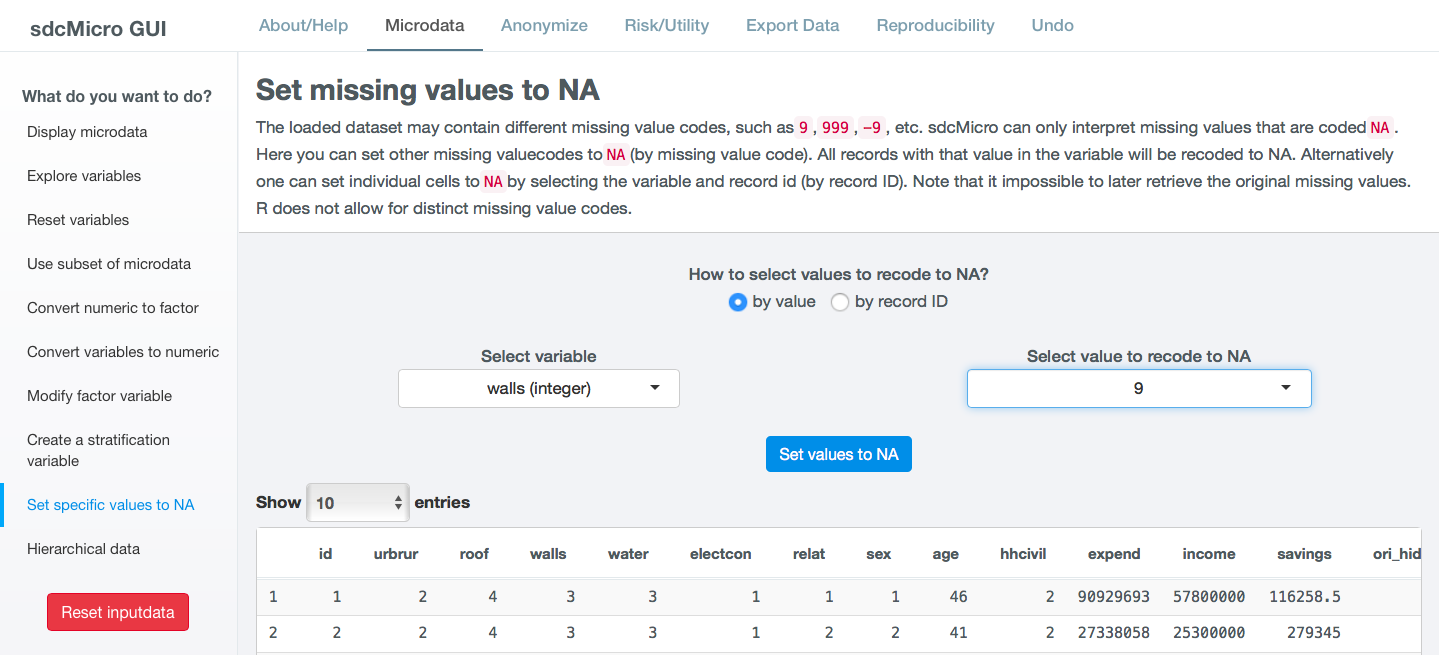
Fig. 20 Screen to set specific value in a variable to NA
Modify factor variable¶
Recoding (see Recoding)
Note
(this note may come in other places as well) sdcApp is an aid for completing the microdata anonymization process. However, sometimes it may be easier and quicker to use other statistical software packages for performing data preparation steps, such as recoding.
Create stratification variable¶
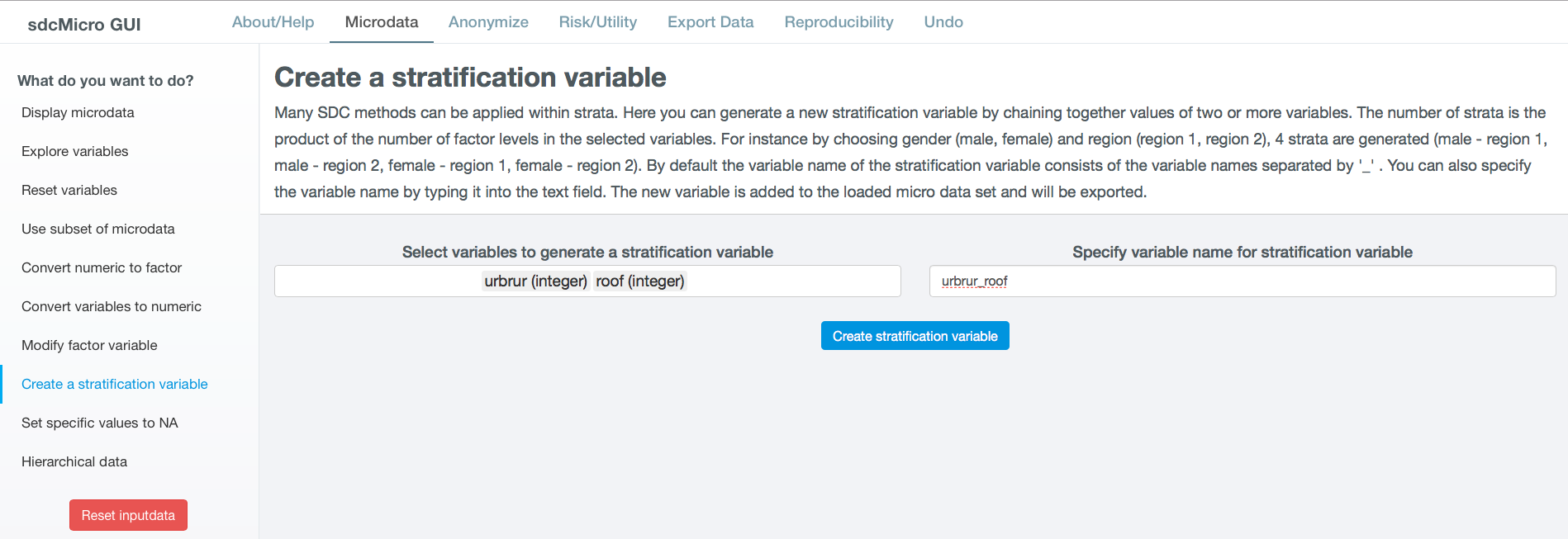
Fig. 21 Screen to create new stratification variable
Reset variables¶
Hierarchical data¶
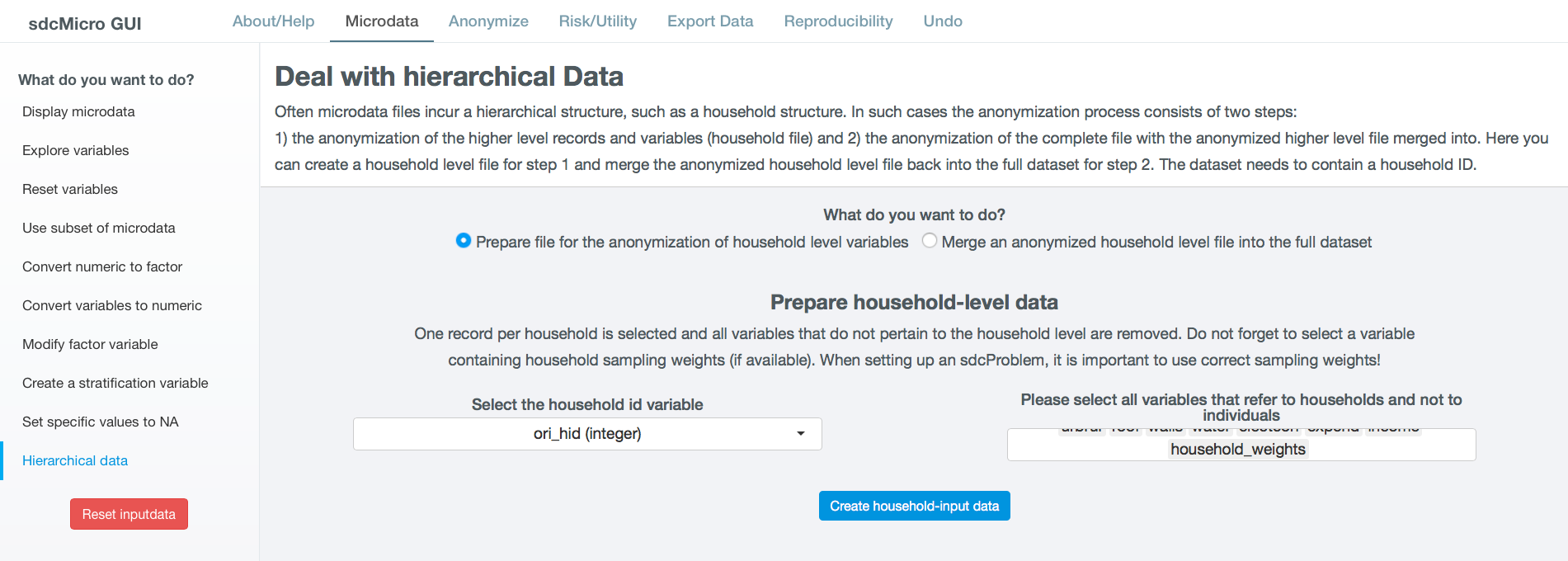
Fig. 22 Screen to create household level dataset
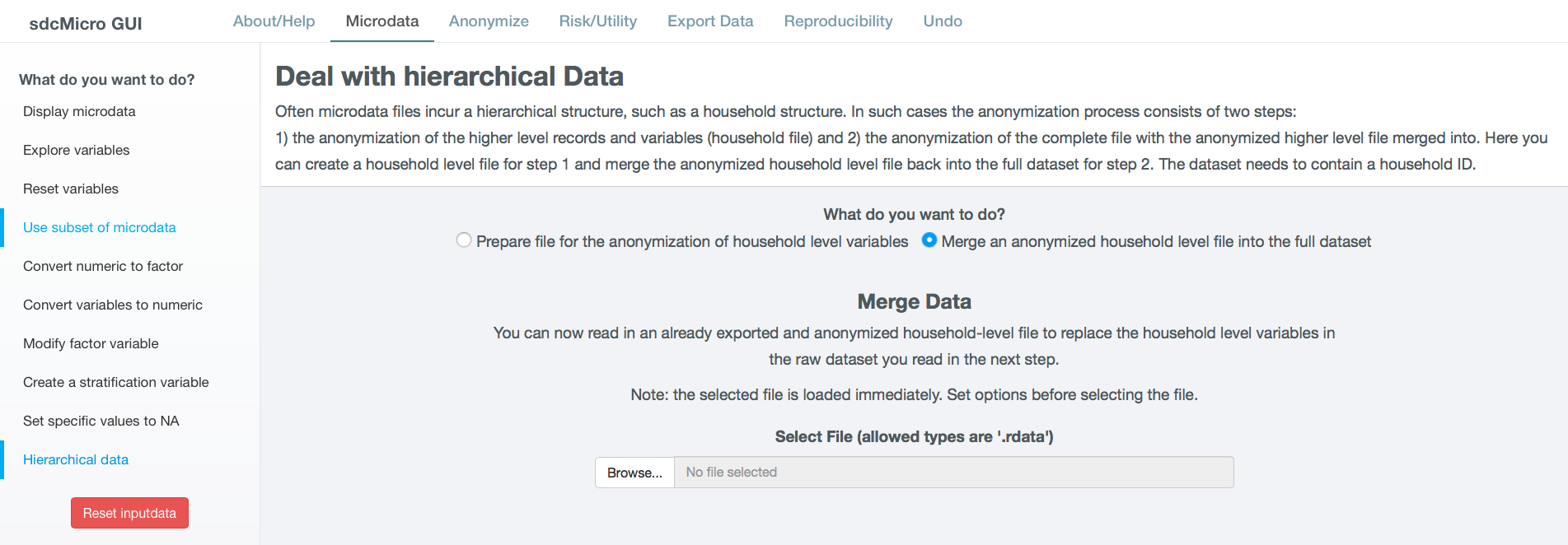
Fig. 23 Screen merge anonymized household level dataset with individual level dataset