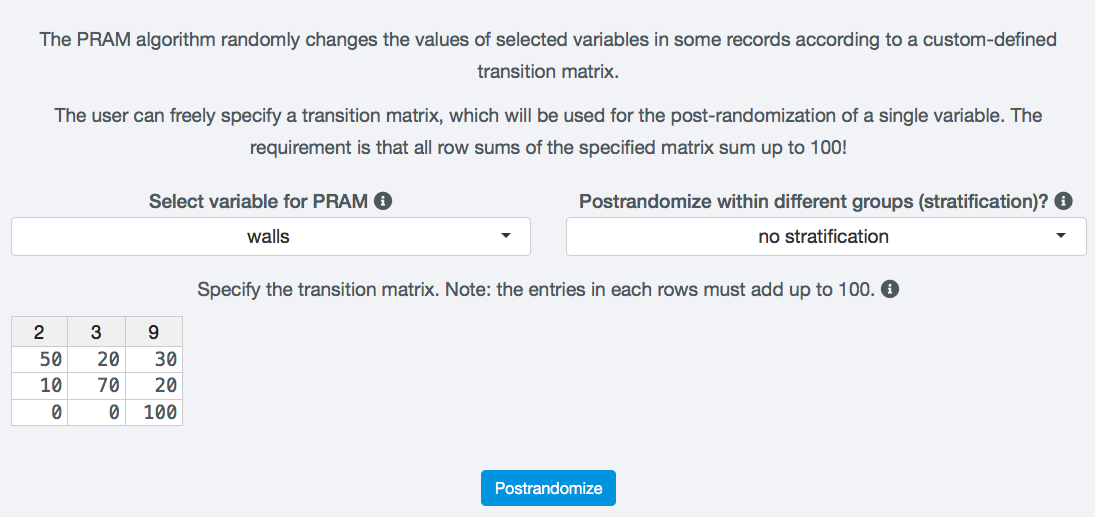
Anonymization Methods¶
Once the disclosure risk is evaluated and is too high for release, SDC methods need to be applied to the variables to reduce the risk. This process is iterative, i.e., after applying a certain method with a set of parameters, the disclosure risk needs to be reassessed and the information loss needs to be evaluated. If the result is not satisfactory, other methods can be applied to other variables. It is also possible to undo the method (see Undo) and reapply the same method with a different set of parameters.
In this section, we provide a brief description of common SDC methods for microdata and show how to use these in sdcApp. For more information on the choice of the appropriate method and more detailed information on the methods themselves, we refer to the section Anonymization methods in Statistical Disclosure Control for Microdata: A Theory Guide.
In order to reproduce the examples in this section, one should load testdata dataset, which is included in the sdcMicro package and follow the steps to setup the SDC problem as outlined in the section Setup Anonymization Problem.
Recoding¶
Recoding is a deterministic method used to decrease the number of distinct categories or values for a variable. This is done by combining or grouping categories for categorical variables or constructing intervals for continuous variables. Recoding is applied to all observations of a certain variable and not only to those at risk of disclosure. In sdcApp two general types are availbale: global recoding and top and bottom coding.
Global recoding¶
Global recoding combines several categories (levels) of a categorical variable or constructs intervals for continuous variables. This reduces the number of categories available in the data and potentially the disclosure risk, especially for categories with few observations, but also, importantly, it reduces the level of detail of information available to the analyst.
In order to perform global recoding in sdcApp, navigate to on the Anonymize tab and select Recoding from the left sidebar. First select the variable to be recoded. In the example in Fig. 32 the semi-continuous variable age is selected. Only variables selected as categorical key variables in the problem setup can be recoded here.
add: distribution is shown to determine breaks: refer to theory guide, also add in screenshot
Next select all the existing levels in the variable to be combined. In the example, we select all values of age equal or larger to 85. Behind each value the number of observations in the dataset with this value is displayed. The label of the variable to be created is by default the concatenation of the labels of all combined values (85_88_90_95), but can be changed to any string. In the example the new label is 85+.
In case the system missing value (:code:NA) should be included in the newly created level, set the option Add missing values to new factor level? to Yes. This could be for example useful if a new group is created combining other and not applicable. The default of this option is No.
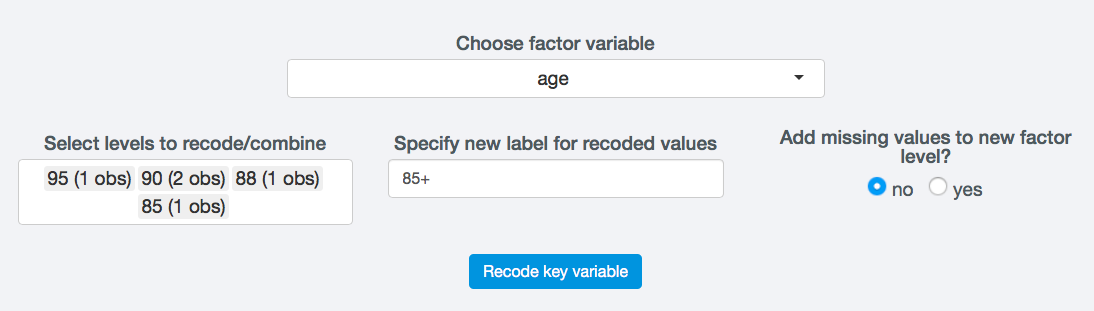
Fig. 32 Settings for global recoding to recode the variable age
After selecting the variable, levels and specifying a new label the variable is recoded by clicking Recode key variable. The risk measures are immediately updated once the method is applied.
Note
When exploring the recoded variable, the old levels still appear in the frequency table. They stay in the variable with 0 observations.
For each group (new level), this process needs to be repeated. If, for example, age should be recoded in 5-year age bands, these steps need to be carried out for each 5-year age group separately.
Tip
Global recoding for a variable with many different levels, such as age, can be a daunting task in sdcApp, as it involves many clicks and is prone to making mistakes. As an alternative, one could perform the recoding in another statistical software before loading the data in sdcApp. This would influence the initial risk levels.
add: Variables can already be recoded before on data tab
Top and bottom coding¶
Top and bottom coding are similar to global recoding, but instead of recoding all values, only the top and/or bottom values of the distribution or categories are recoded. This can be applied only to ordinal categorical variables and (semi-)continuous variables, since the values have to be at least ordered. Top and bottom coding is especially useful if the bulk of the values lies in the center of the distribution with the peripheral categories having only few observations (outliers). Examples are age and income; for these variables, there will often be only a few observations above certain thresholds, typically at the tails of the distribution. The fewer the observations within a category, the higher the identification risk. One solution could be grouping the values at the tails of the distribution into one category. This reduces the risk for those observations, and, importantly, does so without reducing the data utility for the other observations in the distribution.
In order to perform top or bottom coding in sdcApp, navigate to on the Anonymize tab and select Top/bottom coding from the left sidebar. First select the variable to be recoded. In the example in Fig. 33 the continuous variable income is selected. Only variables of type numeric can be top or bottom coded.
add: boxplot to check distribution
Note
Top and bottom coding ca only be applied to numeric variables. If age, as in our example, is converted to factor, the global recoding method needs to be used, in order to topcode age by grouping all values above the threshold.
Next select top or bottom coding. In case of top coding all values above the set threshold are replaced, in case of bottom coding all values below the set threshold are replaced. Set the threshold value and replacement value by entering these in the numeric fields. After entering the threshold and replacement values, the number of records with values below/above the threshold that are replaced is shown.
Note
It is advised to use a replacement value different than the threshold value, such as the weighted mean or median to reduce information loss. The replacement value needs to be computed in a different software and manually inserted in sdcApp.
After selecting the variable, type and specifying the threshold and replacement values, the variable is topcoded by clicking Apply Top/Bottom-Coding. The risk measures are automatically updated after the method is applied.
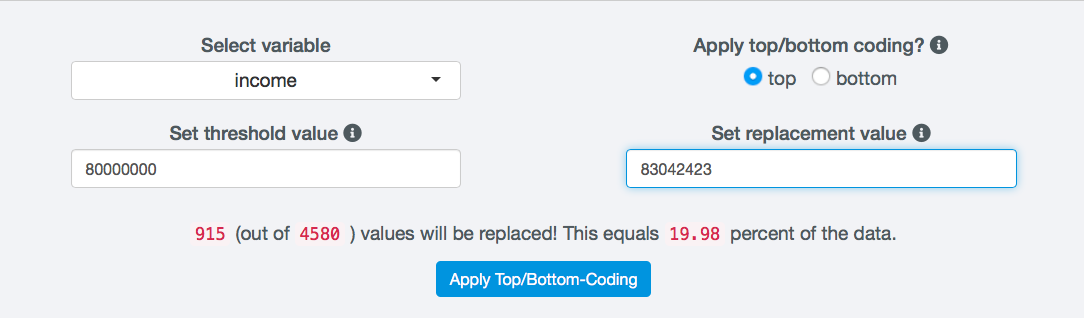
Fig. 33 Settings for topcoding the variable income at 8 million
k-Anonymity / local suppression¶
It is common in surveys to encounter values for certain variables or combinations of quasi-identifiers (keys) that are shared by very few individuals. When this occurs, the risk of re-identification for those respondents is higher than the rest of the respondents. Often local suppression is used after reducing the number of keys in the data by recoding the appropriate variables. Recoding reduces the number of necessary suppressions as well as the computation time needed for computing the suppression pattern. Suppression of values means that values of a variable are replaced by a missing value (NA in R). The the Section k-anonymity discusses how missing values influence frequency counts and k-anonymity.
In order to perform local suppression to achieve k-anonymity in sdcApp, navigate to on the Anonymize tab and select k-Anonimity from the left sidebar. Local suppression is always performed on the complete set off selected categorical key variables.
In order to apply the default local suppression algorithm, the user only needs to set the level of k to be achieved.
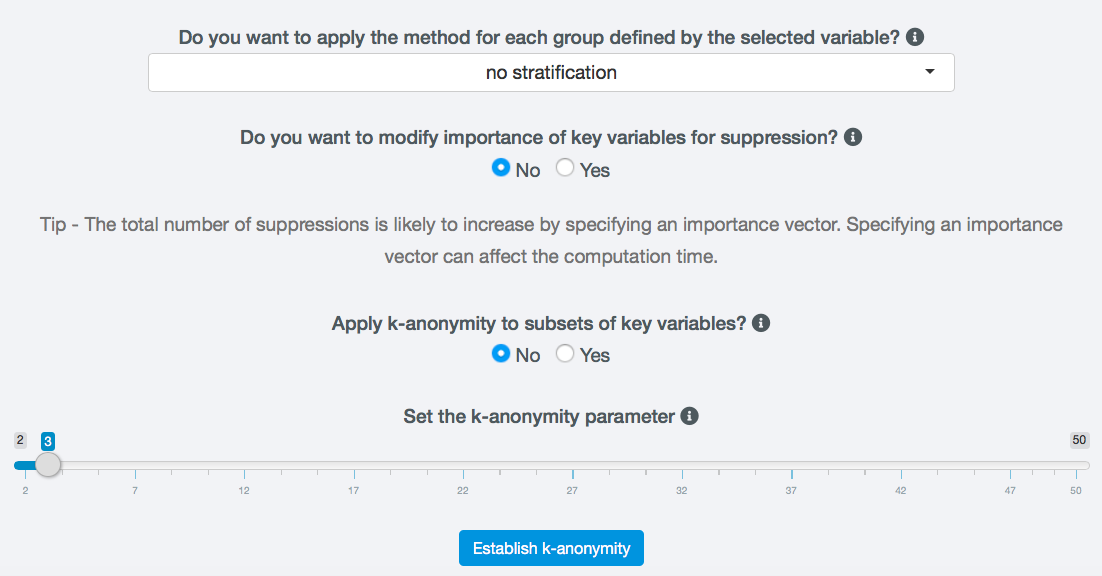
Fig. 34 Settings for local suppression to achieve 3-anonimity
add: overview of suppressions /suppression patterns
Importance¶
By default the algorithm considers variables with many different levels first. Therefore, it is more likely that these variables will contain suppressed values. Sometimes variables with many different levels are important for the

Fig. 35 Importance settings for local suppression
Subsets¶

Fig. 36 Subset settings for local suppression
Suppress values with high risk¶
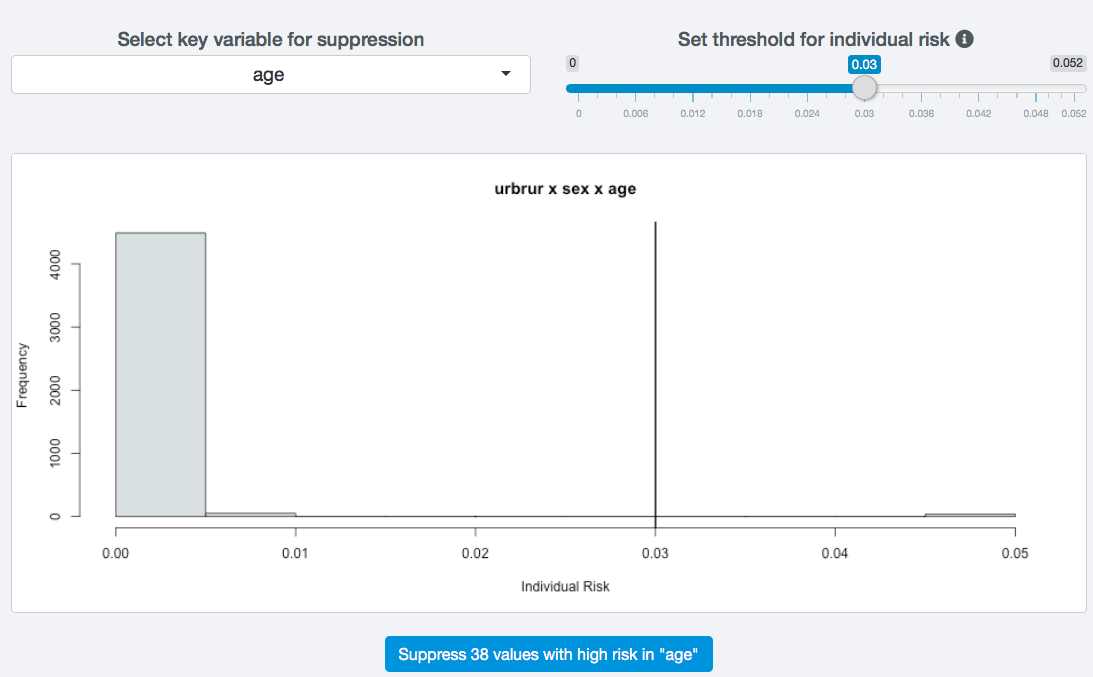
Fig. 39 Settings for suppressing values in records with high risk
Top/Bottom coding¶
Microaggregation¶

Fig. 40 Settings for microaggregation
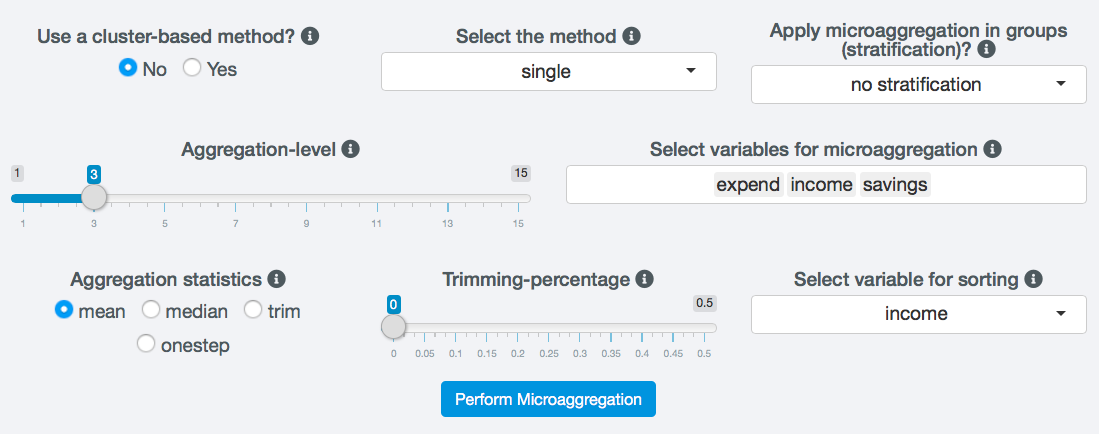
Fig. 41 Additional settings for microaggregation
Fig. 42 Cluster settings for microaggregation
Adding noise¶
Rank swapping¶
Undo¶
Finding an anonymization strategy for a microdata dataset is a trial-and-error process. The effect on risk and utility of different methods with different parameter settings can only be assessed by executing the methods on the actual dataset. Therefore, it is unlikely to find a satisfactory anonymization strategy at the first attempt. Before another method is applied, the previous method needs to be canceled. In sdcApp it is possible to undo the last method applied with one click. To test the effect of a combination of several methods, which is recommended, it is necessary to cancel several steps. To do so, the state of the SDC problem before applying the methods is saved to disk and can be reloaded afterwards. This is the same as canceling several steps. Both methods are described below.
Undo one step¶
In order to undo one step,
risk measures etc are also reset, script not, random seed not